


After the buzz of this notebook frenzy where new things are learned, and progress is made follows the comedown that is about as enjoyable as filing your taxes: Porting the code outside of the notebook for production, integrating it with whatever comes before and after in the pipeline. For an R data scientist, a similar struggle can take place when code lives in an R Markdown notebook.

Notebooks simply don’t integrate well into larger pipelines, and therefore the longer you postpone the backport, the more your technical debt grows. Therefore, the only notebook tracks that aren’t ephemeral are documentation and reporting at the end of data pipelines.
With the maturation of the Databricks platform, this is about to change. Databricks allows you to take your notebook projects to a whole new level, and in this blog post, I’ll tell you how we did just that in one of our latest experiments.
From Python versus R to a combined toolkit

Over the past decade, both R and Python data science communities have flourished after high-quality open source tools filled a gap in a rapidly growing data-driven market. Unfortunately, because of functional overlap in a few of the most popular libraries, such as Pandas and Dplyr, the sentiment has been cultivated that a struggle for dominance is going on between both languages. The creators of said packages, Wes McKinney and Hadley Wickham, respectively, never believed that anything good could come from antagonizing both communities and have publicly spoken out against it.
Recently, this message seems to be sinking in at last, and promising initiatives are being set up by these two visionaries to build cross-platform toolkits.
The Databricks platform seems one of the most promising early adopters of this changing mindset. Not only can you create both R and Python interactive notebooks, but the execution language can also be adjusted on a per-cell basis by initializing them with %r or %python magic commands.
This is precisely what we did for one of our latest projects—allowing us to select the best parts of both toolkits for different parts of the analysis. We ended up building a product recommendation engine and customer segmentation algorithm in Python and sales forecasts with auto-ARIMA plus ggplot2 graphics in R.
Integration
Since Databricks is a managed service within Azure, the setup was done in a matter of minutes. We added an Event grid listener to pick up datafile uploads on the blob storage and then executed an Azure function call to the Databricks API. This call included details on the type of cluster to use and which packages to load. The customer then received emails with the advice provided by our different analyses within the Databricks notebook.
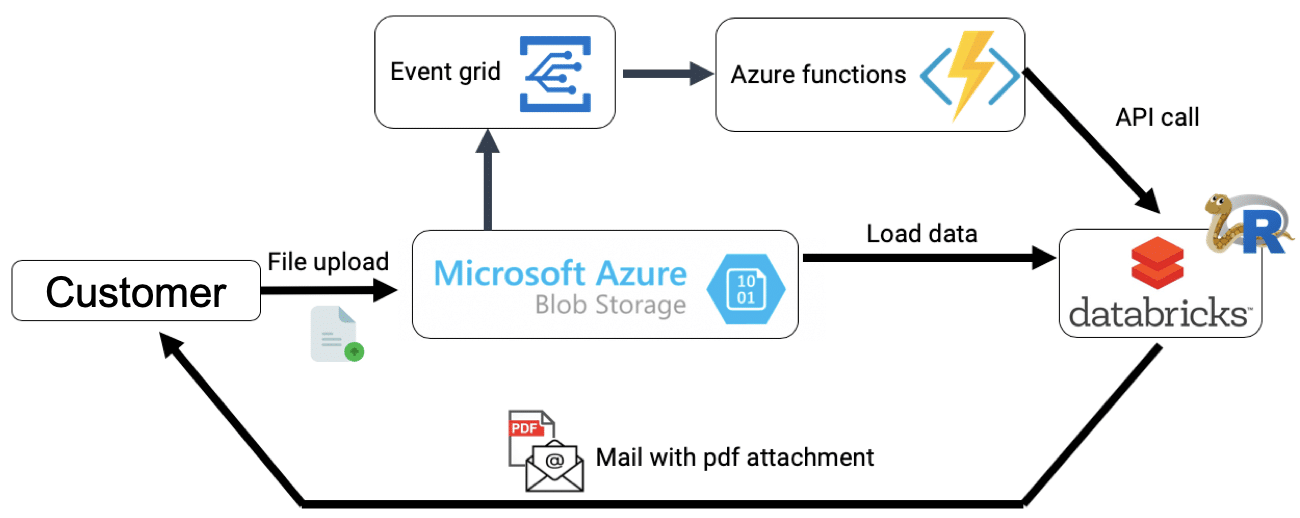
Databricks natively leverages Spark for big data crunching. While this is one of the strong suits of the platform, we didn’t use this part of the stack for this project as the dataset was sufficiently small to load into memory.
Conclusion
Databricks allows data scientists to bring their analyses to the customer without venturing outside of their notebook's comfort zone. The cross-language feature enables you to use the best of both R and Python worlds. We’re not planning to stop writing code outside of notebooks anytime soon but are definitely happy to have this trick up our sleeves.
